We are all getting used to asking Siri, Alexa, and Google to find things via voice. Alexa has more than 30,000 skills and smart speakers grew by 210% in Q1. Clearly voice assistants have matured, which is why it is insane that businesses still make their customers sit through tedious Interactive Voice Response (IVR) systems that rely on archaic touch-tone input and multi-layer menus. Sure, some high-end enterprises might have better systems, but, by-in-large, the IVR experience has not changed much in decades.
I believe this is about to change. I was commenting on Google's recent Duplex demo and Alexey Aylarov of VoxImplant mentioned they were just wrapping up an integration with Dialogflow - the conversational bot company formerly know as api.ai that Google bought and rebranded.
VoxImplant is a Communications Platform as a Service (CPaaS) with most of its team in Moscow. Alexey claimed they could do something similar to Duplex using public API’s (though without many of Google’s more advanced tricks). He has a good history of sharing the workings behind new concept demos, so I asked if he would share his experience and learnings integrating with Dialogflow here. Please see below for Alexey's high-level review of Dialogflow, more details on how VoxImplant went about the telephony integration, and for the more technical, some demos and code at the end.
Chad Hart, Editor
Making IVRs not Suck with Dialogflow
In most cases when we need to communicate with a business over the phone today we have to deal with a good old IVR. “Press 1 to …, press 2 to …, press 3 to …”. Just the initial options prompt itself can last for a few minutes. After you endure this first level of IVR menu comes a 2nd level, which can also lead to the 3rd one, and so on. It can be maddening. I haven’t met anyone who thinks that kind of customer experience is great. Fortunately alternatives to the IVR menu are becoming practical for a large audience. Thanks to the progress in machine learning and IT in general, speech recognition and voice bots have started to become accessible for business.
Rather than navigate through IVR menus, wouldn’t it be better if you could just say what you need/want, like you would with a real operator? That is totally possible with today’s technology natural language processing (NLP) and speech recognition technologies. Let's explore how we did this in our platform using Dialogflow.
Dialogflow
Google’s Dialogflow lets people create intelligent bots that understand natural language and can handle conversations like a live person. Dialogflow supports many nice features out of the box that are a good fit for commonly used in IVR interactions, such as:
- Understanding intents - mapping a variety of spoken phrases to defined action
- Slot filling - handling multiple data inputs per user utterance and knowing to keep asking when more information is required
- Fallbacks - handling errors and avoiding looks if something is not understood
- API and webhooks - for integration with external web services
- Speech recognition - the new V2 API can directly handle speech input from Google’s Cloud Speech API
Dialogflow is a powerful tool that developers can quickly become familiar with after reading the docs and checking some examples. They make it easy to build rather complex bots without programming (or at least serious programming). If you are familiar with modern bot programming, Dialogflow works with number of common bot abstractions you need to set up for your agent to make it work Intents, Parameters, Contexts, Entities, and so on.
Choosing Dialogflow as an integration option was an easy decision for us. We already had a Google Speech integration (see below), so there were minimal technical challenges on our end. We also found it works well for our audience, and their documentation and examples are great, so we not think our users will have much trouble getting started with their API.
There are already a lot of articles and posts about Dialogflow and how to build various kinds of bots. Rather than rehash these guides, instead we will focus the rest of this post on how to integrate Dialogflow into a telephony system.
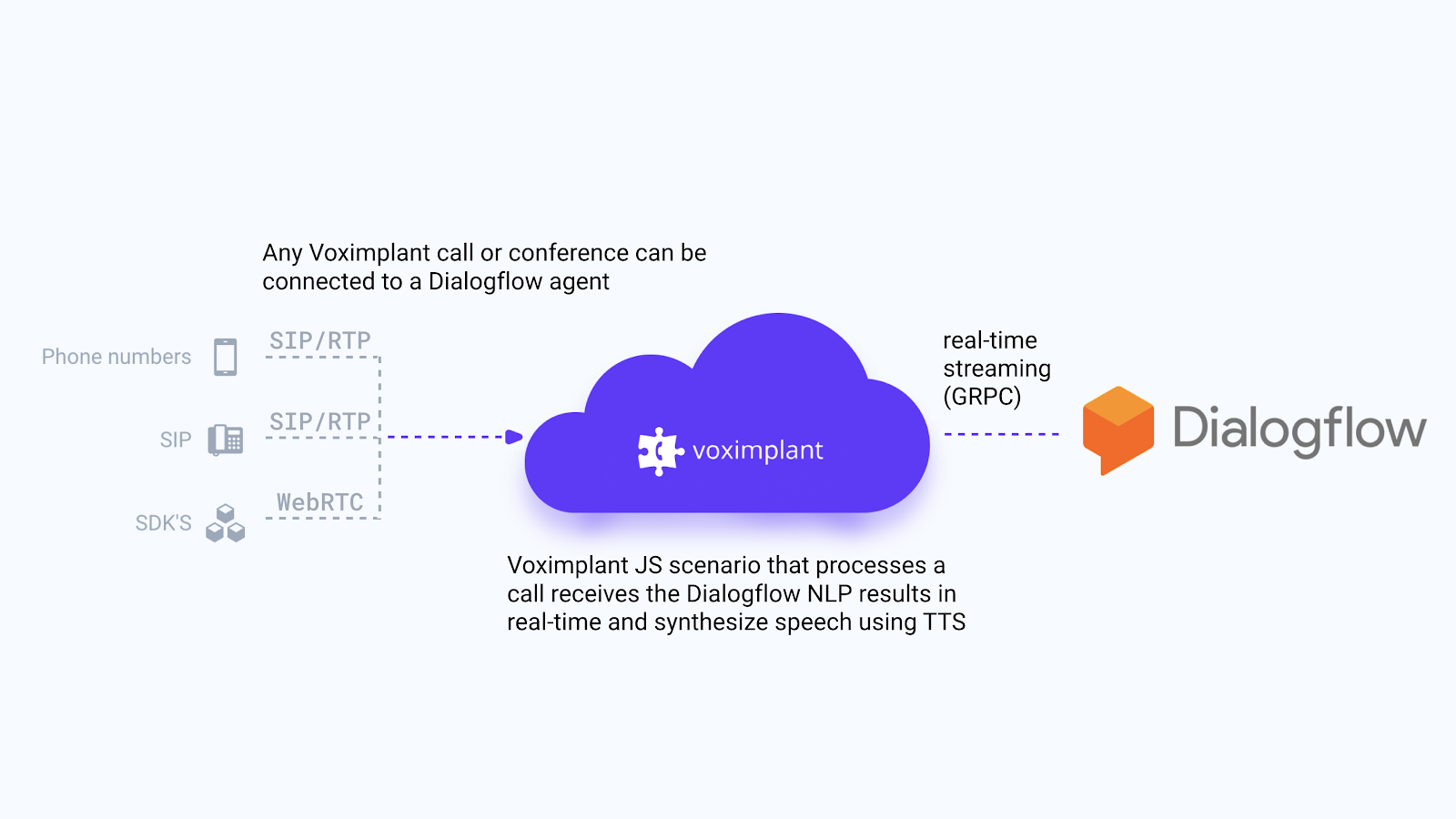
Telephony Considerations
Transcription Integration
Before API V2, Dialogflow agents could only work with text. That means you had to handle converting any speech to text yourself. Then you could pass that text to the API and receive response from an agent after NLU/NLP job has been done. In the new API V2 there is a StreamingDetectIntentRequest method that lets send audio directly to a Dialogflow agent. This method will transcribe the speech and then automatically process the transcription to create a response. It turns out this new method is basically the same as the Google Cloud Speech API.
You can still handle your own speech recognition, but is really easier to use Google’s methods. Google’s Cloud Speech API allows uploading of a recording, but you really should be streaming the audio to reduce latency and prevent awkward silences while audio is processed. Google uses the GRPC protocol for streaming your audio data in real-time to Dialogflow. Unfortunately I do not think there is any magic method for how to convert a live audio stream into GRPC. Ultimately you need some kind of converter that takes the stream from your system, chunks it up, and then sends it over GRPC. We had already integrated Google’s Cloud Speech API into Voximplant for automatic speech recognition with our own library, so it was relatively easy for us to add Dialogflow’s streaming API support.
Codecs
One of the first areas you will need to align-on is the audio encoding. Google supports Linear PCM, FLAC, G.711 PCMU, AMR/AMR-WB, OPUS in OGG container and Speex Wideband. Your telephony system definitely supports one of these, so it is just a matter of matching the codec whatever the caller is using. We do a lot of PSTN audio processing at our backend, so we usually use PCM. One could use an encoding that does more compression to reduce bandwidth consumption, but it is important to remember that additional transcoding/audio processing significantly affects recognition accuracy. Compressing the audio stream only makes sense if you already receiving the encoded audio in the format supported by Google’s backend.
Speech Duration Modes
Dialogflow/Google Speech supports two speech recognition modes:
- Single utterance - recognition stops as soon as Dialogflow decides that user stopped talking and processes the sentence using NLU/NLP. (
singleUtterance = true) - Long running - you send speech and recognition will continue until it’s stopped using the API so everything is transcribed and sent through the NLU/NLP engine. (
singleUtterance = false)
The long running mode also gives interim recognition results that arrive in StreamingRecognitionResult objects. These can be used by the NLU engine to predict an intent before speech even stops, like what happens with a person.
Returned Result
After NLU/NLP is done, the Dialogflow agent returns a QueryResult object populated with some data - action, intent, contexts, etc. (see the next section for a code example). For example, it can be used by telephony backend to say something using Text-to-Speech (TTS) engine or to change IVR branch, or to connect with a live person, etc. We had an existing Text-to-Speech capability for the many languages we support, but recently added Google’s Text-to-Speech with WaveNet-powered voices. The WaveNet TTS engine sounds very realistic, but unfortunately it is only available for US English today. We do expect that new languages will appear in the not too distant future. I also expect that Dialogflow will support sending audio generated by Google’s TTS at some point too.
Demo & Code
If you want to try it in action you can play with our pizza order & delivery phone bot here:
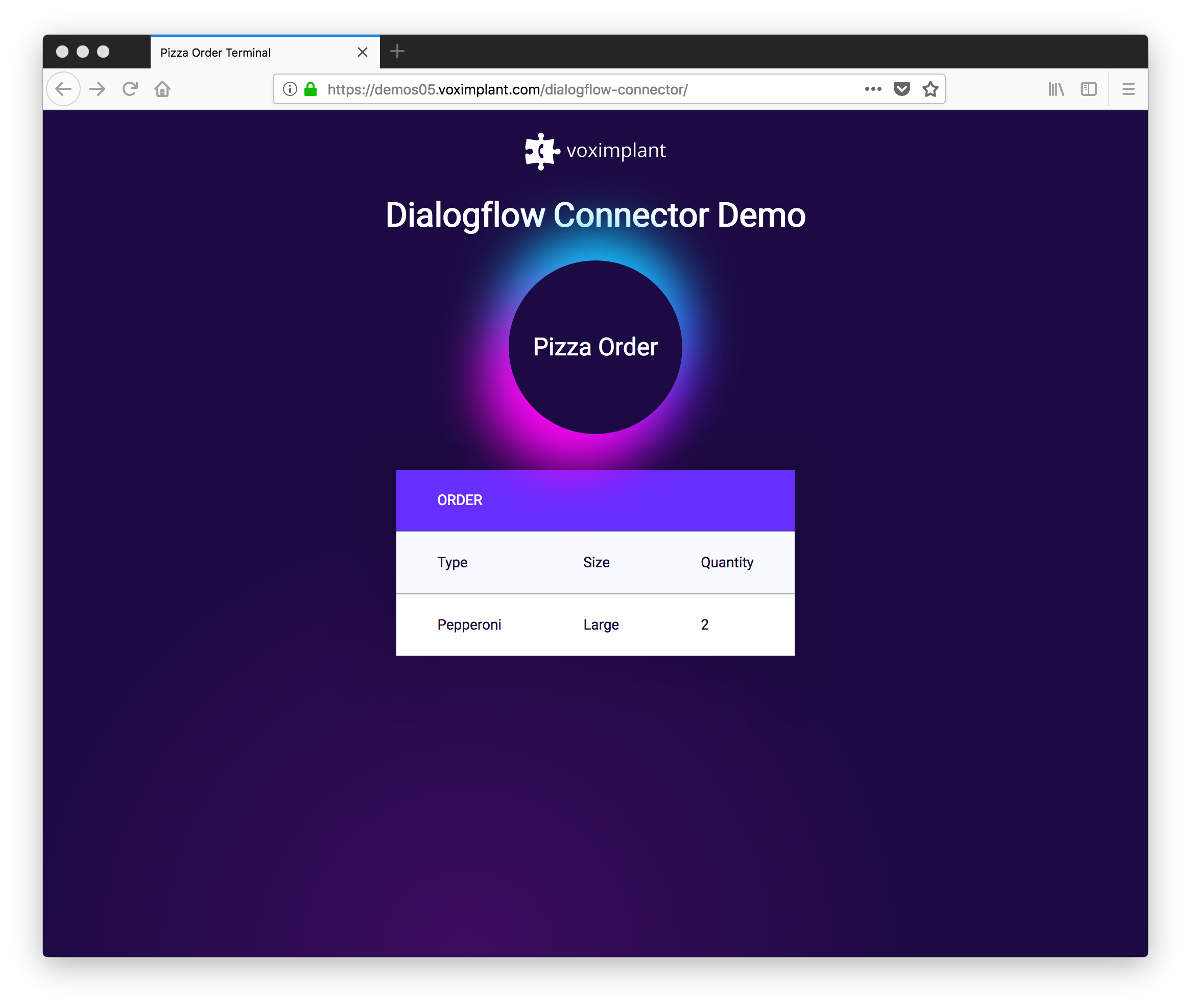
Dialogflow allows you to import a project, which makes it easy to get started by modifying an existing application through the GUI. You can grab the Dialogflow agent used in this demo here: PizzaOrderDelivery.zip.
You can see from the demo that some of the interpreted information is relayed back to the webpage as a visual confirmation. To do this we setup a NodeJS proxy in our backend to send the interpreted responses from Dialogflow to the local browser. We plan to add websocket support to our API engine to make this easier.
On our side, we use something like the below cloud function to process the returned QueryResult object and respond with Text-to-Speech:
function sendMediaToDialogflow() {
call.removeEventListener(CallEvents.PlaybackFinished)
call.sendMediaTo(dialogflow)
}
function onDialogflowQueryResult(e) {
if (e.result.fulfillmentText !== undefined) {
call.say(e.result.fulfillmentText, Language.Premium.US_ENGLISH_FEMALE)
call.addEventListener(CallEvents.PlaybackFinished, sendMediaToDialogflow)
}
}
Many of the function calls are obviously specific to our implementation, but one can see how similar logic could be used implement something like Google’s Duplex demo for outbound calls too!
- Alexey Aylarov, CEO VoxImplant






Comments